Die 7 Aufgaben im Data Science Management
- Author
 Martin SchmidtImpact Distillery
Martin SchmidtImpact Distillery- Author
 Prof. Dr. Marcel HebingImpact Distillery
Prof. Dr. Marcel HebingImpact Distillery
Dieser Artikel erschien zuerst in englischer Sprache als The 7 Tasks in Data Science Management auf Towards Data Science.
In allen Wirtschaftsbereichen entstehen stetig neue Anwendungsfälle für Data Science. Und mit ihnen wächst von KMUs (Kleinen und Mittelständigen Unternehmen) bis hin zu Großkonzernen die Anzahl an Data Scientists sowie die Größe und die Komplexität der Teams, die an zu lösenden Fragestellungen arbeiten. Dabei zeigt sich jedoch, dass nur eine geringe Anzahl von Data Science Projekten (22%) nennenswerte Umsätze generieren und dass ein Großteil der Projekte schlichtweg scheitert (60 bis 85%) (Atwal 2020). Dies wirft die Frage auf: Wie gehen wir mit der wachsenden Komplexität des Managements von Data Science um?
In diesem Artikel wollen wir
- definieren, was Data Science Management ist,
- die Vorteile für die Entwicklung einer Data Science Kultur verdeutlichen,
- die Aufgaben von Data Science Manager*innen und deren Notwendigkeit im Unternehmen aufzeigen,
- die Notwendigkeit für Data Science Manager*innen in Unternehmen aufzeigen
- und überlegen, wie entsprechende Kandidat*innen für den Job gefunden werden können.
Was ist Data Science Management?
Data Scientists sind u.a. gut ausgebildete Informationswissenschaftler*innen, Naturwissenschaftler*innen, Sozialwissenschaftler*innen und Mathematiker*innen. Einige haben sogar Data Science als eigenständige Disziplin studiert, nachdem entsprechende Studiengänge seit jüngster Zeit angeboten werden. Sie lösen praktische Probleme in den Unternehmen, hinterfragen eingefahrene Routinen und lieben die Welt der Zahlen. Sie geben Einblicke in komplexe Prozessabläufe, analysieren gigantische Datensätze und stellen sich immer neuen Herausforderungen. Sie helfen durch automatisierte Prozesse Zeit zu sparen und gestalten die Zukunft der Unternehmen mit. Doch manchmal verbeißen sich Data Scientists leider auch mal in ein Problem und verlieren den Fokus auf die eigentlichen Herausforderungen. Das ist der Moment, wo Data Science Manager*innen ins Spiel kommen.
Um einen strategischen Vorteil zu erlangen, müssen Unternehmen zunehmend die Potenziale von Daten aus vielfältigen Datenquellen erschließen, diese zusammenführen und in anwendbares Wissen überführen. In vielen Fällen entsteht dabei der Fehlschluss, mehr Daten ("big data") sei automatisch besser, was leider nicht immer zutrifft. Vielmehr brauchen wir die richtigen Daten, passend zur jeweiligen Fragestellung. Dies nennen wir häufig "smart data". Smart Data fokussiert die Diskussion auf die Art und Weise wie Daten ergebnisorientiert zusammengeführt und aufbereitet werden, um so die wesentlichen Herausforderungen angehen zu können (Iafrate 2015).
Viele Unternehmen stellen bereits eigene Data Scientists an. Die Arbeitgeber-Arbeitnehmer-Beziehung birgt jedoch Enttäuschungspotenzial: Unternehmen sind häufig nur unzureichend darauf vorbereitet, sowohl was die technischen Infrastrukturen als auch die Einbindung dieses neuen Berufsbilds in die Organisationsabläufe angeht. Solche Fehler führen dazu, dass Data Scientists nicht ihre Stärken ausspielen können. Die Data Scientists auf der anderen Seite fühlen sich dann häufig unterfordert und fangen an sich zu langweilen, was wiederum zu Frustration führt. Im schlimmsten Fall zahlen Unternehmen also viel Geld für Data Scientists, die aufgrund der gegebenen Arbeitsbedingungen ihre Potenziale nicht entfalten können.
Entwicklung einer datengetriebenen Organisationskultur
Data Science Manager*innen sind sich dieser Fallstricke von Anfang an bewusst und können sowohl Unternehmen als auch neue Kandidatinnen und Kandidaten optimal auf die Zusammenarbeit vorbereiten. In Abbildung 1 finden sich einige praktische Maßnahmen, welche durch sie in der täglichen Arbeit gut umgesetzt werden können, um eine datengetriebene Organisationskultur im Unternehmen zu fördern:
Siehe auch: Fünf erste Schritte zu einer datengetriebenen Organisationskultur
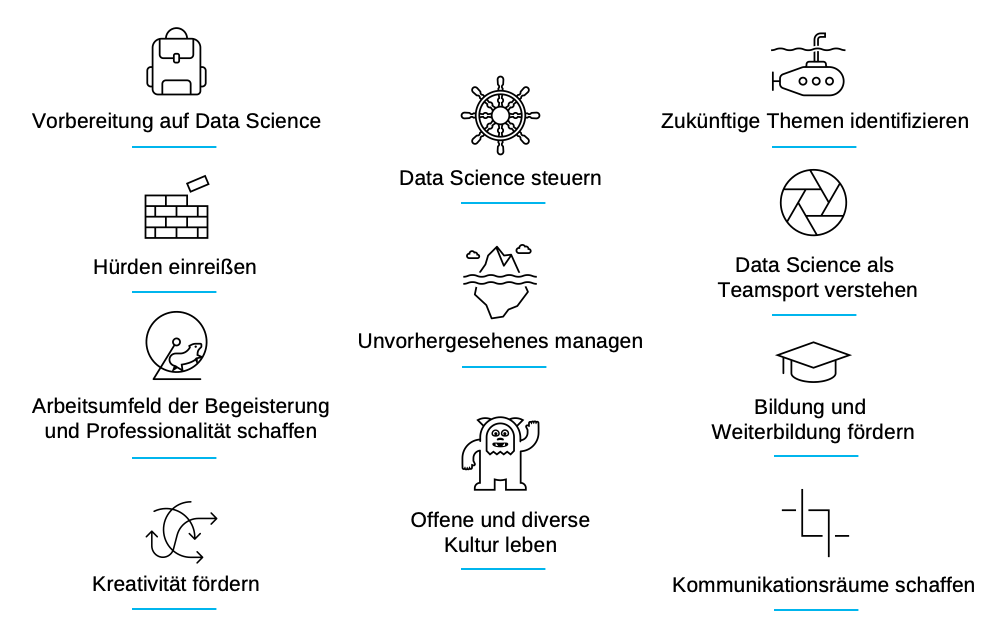
Abbildung 1. Wesentliche Bausteine, um eine datengetriebene Organisationskultur im Unternehmen aufzubauen, welche erfolgreiche und nachhaltige Data Science Projekte ermöglicht. Abbildung der Autoren (CC BY 4.0).
Data Science Manager*innen denken voraus. Sie müssen erkennen, welche Themen und Fragestellungen im Unternehmen an Bedeutung gewinnen, um die Data Scientists im Team rechtzeitig darauf vorbereiten zu können. Sie wollen Barrieren abbauen (vor allem beim Datenzugriff) und schaffen notwendige Austauschformate und Informationskanäle (Bhatti 2017). Da Data Science eine Art Teamsport ist, sollten Data Science Manager*innen motivieren im Team zusammenzuarbeiten und ein Gefühl der Zusammengehörigkeit schaffen.
Und letztlich brauchen Data Science Manager*innen auch ein gutes Stück Handlungs- und Entscheidungsfreiheit. Data Scientists arbeiten in einem sich stetig weiterentwickelnden Feld, daher sind auch entsprechende Ressourcen, beispielsweise um an Konferenzen und Weiterbildungen teilnehmen zu können, notwendig. Im Hinblick auf die gesamte Unternehmung sollten Data Science Manager*innen dabei mehr als Botschafter*innen denn als Führungskräfte verstanden werden, welche für den optimalen Einsatz von Data Science Technologien einstehen.
Aufgaben der Data Science Manager*innen
Im Arbeitsalltag von Data Science Manager*innen gibt es ein ganzes Set von wiederkehrenden Aufgaben, welche wir in Abbildung 2 zusammengestellt haben. Auch wenn es viele Überschneidungen zu (agilen) Software-Entwicklungsteams gibt, stechen ein paar Punkte heraus. Im Folgenden wird auf diese Punkte näher eingegangen.
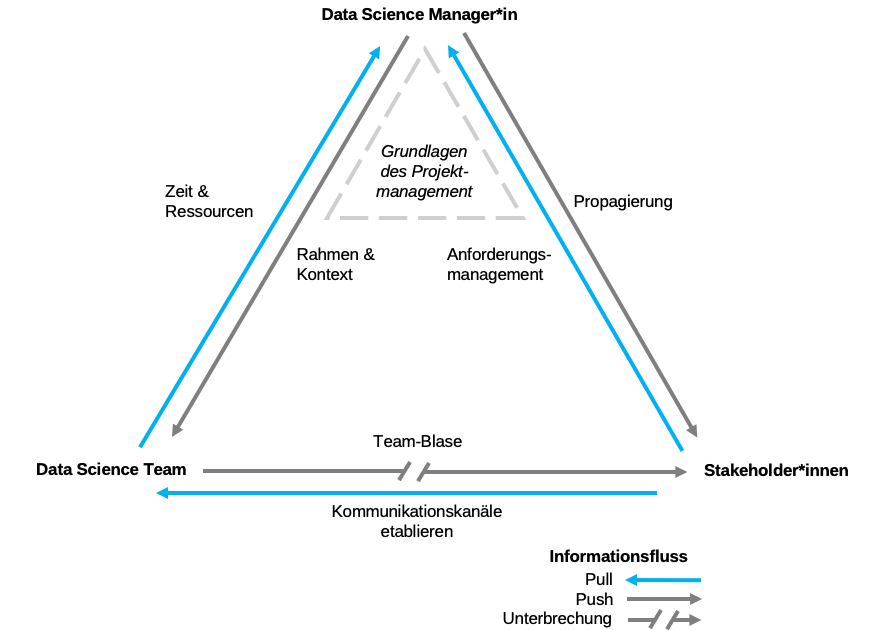
Aufgabe 1) Anforderungsmanagement
Der Ausgangspunkt für die meisten Data Science Projekte ist das Gespräch mit den Stakeholdern, um herauszufinden, was deren Anforderungen und Wünsche an das Projekt sind. Es geht also vor allem darum, Informationen zu sammeln und ein besseres Verständnis für das business problem zu entwickeln (vgl. Shearer 2000). Es ist wichtig über Erwartungen zu sprechen, wobei letztlich die Frage beantwortet werden soll, was sich für die Stakeholder verändert haben wird, sobald das Data Science Projekt abgeschlossen ist.
Die gesammelten Anforderungen müssen dann in analytische Fragestellungen bzw. Aufgaben übersetzt werden, welche von Data Scientists bearbeitet werden können (Provost and Fawcett 2013). Weiterhin sollte der Umfang der Aufgaben in gut handhabbare Pakete gegliedert werden, welche beispielsweise zunächst in einen backlog gesammelt und in user stories übersetzt werden, wie es auch in der (agilen) Softwareentwicklung üblich ist (Scrum.org).
Aufgabe 2) Zeit und Ressourcen
Die Arbeit an komplexen Aufgaben ist meistens auch mit Unsicherheiten verbunden. Entsprechend muss die Komplexität reduziert werden, um die Projektkosten zu kalkulieren und entsprechend das zur Verfügung stehende Budget planen zu können. Für die Stakeholder kann es hilfreich sein, die Kosten an den user stories festzumachen. Aber wie schon angedeutet bedeutet Komplexität auch immer, dass mit verschiedenen Arten von Unsicherheiten umzugehen ist. So ist es beispielsweise eine gutes Vorgehen, Zeitpuffer in die Planung einzubauen, deren Umfang sich insbesondere am Ausmaß der Unsicherheiten orientierten sollte. Weiterhin bietet der Canvas of Uncertainty (vgf. Abbildung 3) eine gute Struktur, um user stories nach Komplexität und Unsicherheiten zu sortieren, um so einen besseren Überblick zu gewinnen.

Abbildung 3. Die Rumsfeld Matrix kann als Canvas of Uncertainty genutzt werden (Fournet 2019). Welche Faktoren sind bereits bekannt (und können berechnet werden), wo fehlen Informationen, welche aber dritte potentiell haben (nachfragen!), welche Informationen sind unbekannt und werden es wohl noch eine Zeit lang bleiben (beispielsweise Börsenwerte oder das Wetter) und wie umfangreich sind für gewöhnlich komplett unerwartete Dinge, welche unsere Planung durcheinander bringen werden? Aufgrund des letzten Aspekts multiplizieren manche Software-Manager ihre Schätzungen am Ende noch mal mit einem bestimmten Faktor (beispielsweise Pi, also ~3.14159), um besser darauf vorbereitet zu sein (Strom 2008). Abbildung der Autoren (CC BY 4.0).
Es ist unerlässlich, dass Mitarbeitende mit den jeweils notwendigen Kompetenzen für das Projekt bereitstehen. Und vor allem müssen sie auch die zeitlichen Kapazitäten haben, sich entsprechend einzubringen. Dabei geht es natürlich auch darum, die Beteiligten nicht mit zu vielen Projekten gleichzeitig zu überlasten, auch weil mit der Anzahl der Projekte die Transaktionskosten durch den Wechsel zwischen den Projekten schnell ansteigen (Weinberg 1975). Wenn eine bestimmte Aufgabe nur von einer einzigen Person im Team gelöst werden kann, stellt dies automatisch ein Risiko für das gesamte Projekt dar. Ebenso ist bereits im Vorfeld die Verfügbarkeit der Daten sicherzustellen. Es gibt wohl kaum eine unnötigere Verschwendung von Ressourcen als gelangweilte Data Scientists, wenn die Daten zur Arbeit nicht verfügbar sind.
Um einen Überblick über Zeit und Ressourcen zu bekommen, bieten sich die folgenden Fragen an (angelehnt an Seiter 2019):
- Team: Welche Expertise ist erforderlich? Sind die richtigen Mitarbeitenden an Bord und haben sie ausreichend zeitliche Kapazitäten?
- Daten: Welche Daten stehen zur Verfügung (in-house, offene Datenquellen oder durch Zukauf) und bieten sie eine entsprechende Datenbasis, um die vorliegenden Forschungsfragen bearbeiten zu können? Ist es notwendig eine eigene Datenerhebung durchzuführen (beispielsweise eine Befragung)?
- Infrastruktur: Stehen die notwendigen Ressourcen zur Verfügung (Software, Hardware, Cloud)?
Diese Fragen sollten auch helfen, ggf. vergessene Stakeholder oder Personen zu identifizieren, die noch einzubeziehen sind (beispielsweise die IT- oder Rechtsabteilung).
Aufgabe 3) Promotion
Projektfortschritt und -ergebnisse müssen Stakeholdern in der Form präsentiert werden, dass alle „auf einem Nenner" sind. Data Science Manager*innen müssen sich darauf vorbereiten, dass die Komplexität der Fragen mit Fortschreiten des Projekt durchaus steigen können – wenn das entsprechende Produkt sich entwickelt und greifbarer wird, werden die Stakeholder auch genauer in einzelne Details gehen wollen.
Entsprechend ist es hilfreich auch schon vorläufige Ergebnisse in regelmäßigen Abständen zu reviewen und im Blick zu behalten, wie es sich beispielsweise aus einem Sprint-Design – wie in Scrum – ergibt (Scrum.org). In vielen Fällen macht es Sinn, dabei ausgewählte Stakeholder einzubeziehen, insbesondere auch in Hinblick auf mögliche zukünftige Projekte. Wenn Stakeholder sich gut abgeholt und informiert fühlen, steigen auch die Chancen für erfolgreiche Kooperationen in der Zukunft.
Aufgabe 4) Rahmen und Kontext
Schauen wir noch einmal auf das Team. Jedes Mitglied sollte die Vision des Projekts und seine Roadmap (inklusive Zeitplanung) kennen und verstehen. Dabei sollte aber auch jeder und jede über aktuelle Entwicklungen im Projekt informiert sein und ggf. die Möglichkeit haben, eigene Gedanken und Überlegungen einzubringen. Gleichzeitig müssen Data Science Manager*innen aber manchmal auch die Spaßbremse sein, die sicherstellt, dass das Projekt den Fokus auf das angestrebte Ziel behält und die Teammitglieder sich nicht in Nebensächlichkeiten verlieren, auch wenn diese manchmal unterhaltsamer und interessanter wirken mögen als die eigentlichen Arbeitsaspekte.
Aufgabe 5) Kommunikation fördern und moderieren
Soweit es dem Projekt zuträglich ist, sollten Data Science Manager*innen die Kommunikation zwischen Projektteam, Stakeholdern und anderen Parteien fördern und moderieren. Insbesondere sollten Prozesse, Methoden und Ziele gut zwischen allen Beteiligten abgestimmt und kommuniziert werden.
In Abbildung 2 ist diese Aufgabe als pull-Beziehung modelliert, bei der das Data Science Team notwendige Informationen von den Stakeholdern erhält. Dies ist ein ganz wesentlicher Aspekt unseres Modells: Das Team bekommt zwar die notwendigen Informationen der Stakeholder, ist aber andersherum ein Stück weit von Anfragen seitens der Stakeholder abgeschirmt (siehe nächster Punkt).
Aufgabe 6) Team Bubble
Weitergehende Probleme sind so gut wie möglich vom Data Science Team fernzuhalten, damit dieses sich bestmöglich auf die inhaltlichen Aufgaben konzentrieren kann. So kann es beispielsweise helfen, coding days einzuführen oder den Vormittag für konzentrierte Arbeit zu reservieren.
Leider ist eine perfekte team bubble in der Realität meist sehr unrealistisch, auch weil Anforderungen regelmäßig mit den Stakeholdern nachjustiert werden müssen. Wenn dabei nicht alle Informationen vorliegen, kann es wichtig sein, die entsprechenden Data Scientists in Meetings einzubeziehen.
Graham (2009) unterscheidet dabei maker (das Team) und manager (Data Science Manager*innen und die meisten Stakeholder) in Bezug darauf, mit welcher Zeiteinteilung sie am besten und effektivsten arbeiten können. Während es für Data Science Manager*innen und Stakeholder absolut normal sein mag, den Tag in einstündigen Einheiten zu planen und dann von Meeting zu Meeting zu wechseln, wäre diese Zeiteinteilung das Schlimmste, was man dem Data Science Team zumuten könnte. Dies braucht deutlich längere Zeitintervalle (4+ Stunden) für ununterbrochene, konzentrierte Arbeit. Und ununterbrochen meint dabei wirklich ohne jede Unterbrechung von außen – selbst vermeintlich kleine Unterbrechungen von 5 Minuten brauchen im Anschluss häufig 20–30 Minuten, um wieder zur Aufgabe zurückfinden und voll konzentriert weiterarbeiten zu können.
Aufgabe 7) essentielles Projektmanagement
Die meisten Data Science Projekte brauchen essentielles Projektmanagement. Sobald Zeit und Ressourcen geplant sind (siehe oben) kann ein Zeitplan entwickelt werden, was je nach Methode unterschiedlich schwierig sein kann. Einige Dinge sind grundsätzlich zu beachten:
- Ziele im Blick behalten, den Projektfortschritt monitoren und die finanziellen Ressourcen überwachen,
- Qualität von Prozessen und Ergebnissen sichern,
- Dokumentation, Aufgaben und Meetings organisieren und pflegen,
- Urlaube, Krankheitstage und ggf. Trainings im Blick behalten und
- das Team motiviert und zufrieden halten.
Wie finden wir Data Science Manager*innen?
"Managers coming from software engineering or business side functions (finance, accounting, etc.) can have trouble understanding data scientists and defining their project work." (vgl. Jee 2019)
Das Management von Data Science Projekten ist nicht mit dem Management von Gütern und Ressourcen gleichzusetzen. Hard- und Software spielen zwar auch eine Rolle, aber am wichtigsten sind die beteiligten Menschen. Im Bereich von Data Science finden wir vor allem Personen mit einem akademischen Hintergrund, nicht selten auch promoviert, aus verschiedenen Forschungsbereichen. Darin unterscheidet es sich von klassischer Softwareentwicklung und den meisten anderen Funktionsbereichen im Unternehmen (vgl. Jee 2019). Der hohe Bildungsgrad kommt meist auch mit hohen Gehaltsansprüchen und Erwartungen an die Arbeitsbedingungen, auch in Hinblick auf Selbstverwirklichung, selbstverantwortliches Arbeiten und Mitbestimmung. Diese Punkte gelten für Data Scientists, aber natürlich auf für Data Science Manager*innen.
Auch wenn bereits die ersten Hochschulen und Universitäten damit begonnen haben, Data Science Manager*innen auszubilden, wird es wohl noch ein paar Jahre dauern, bis dieses neue Berufsbild sich etablieren kann. In der Zwischenzeit werden Unternehmen wohl primär Personen für diese Aufgaben anheuern, die sich in anderen Disziplinen entsprechend spezialisiert haben und ihre Perspektive erweitern wollen. In den meisten Fällen wird dies bedeuten, einen Nerd zu engagieren, der besonderes Interesse an Kommunikations- und Managementaufgaben mitbringt – zugegebenermaßen eine seltene Kombination.
Data Science Manager*innen sollten analytisches Denken, Erfahrung im wissenschaftlichen Arbeiten und Sicherheit im Umgang mit Komplexität mitbringen – wir suchen einen klugen Kopf mit viel Neugierde. Data Science Manager*innen sollten sicher bei Kunden und vor dem Management präsentieren und verhandeln können, aber genauso auch im Team Anerkennung finden, beispielsweise dafür, jede Berechnung auf 42 hinauslaufen zu lassen (wenn sie diese Referenz nicht verstehen, sollten Sie dringend eine*n Data Science Manager*in engagieren).
Zusammenfassung
Data Science Management ist für jedes Vorhaben unerlässlich, das seine Prozesse mit datengetriebenen Entscheidungen optimieren will. Dies umfasst die Organisation von iterativen Prozessen mit dem Ziel, neue Einsichten mithilfe von wissenschaftlichen Methoden zu gewinnen, genauso wie die Automatisierung von daten- und softwarebasierten Infrastrukturen, um Geschäftsziele zu erreichen. Best practices betreffen hierbei das Anforderungsmanagement, die Verwaltung von Zeit und Ressourcen, die Interaktion mit Stakeholdern und die Anleitung des Teams. Dabei bedeutet Data Science Management insbesondere, Kommunikationskanäle zu etablieren, eine team bubble für fokussierte Arbeit zu schaffen und ganz grundlegendes Projektmanagement umzusetzen.
Nach heutigem Stand sind analytisches Denken, Programmiererfahrung und ein grundlegendes Verständnis von Data Science ganz wesentliche Teile einer Unternehmensentwicklung. Für viele Unternehmen ist es inzwischen selbstverständlich, sich zunehmend auf digitale Geschäftsmodelle zu konzentrieren, basierend auf Methoden des Data Minings und Machine Learnings. Die Entwicklung eines datengetriebenen Geschäftsmodells ist ein komplexer Prozess mit vielen Fallstricken. Entsprechend klug ist es schon jetzt, Data Science Manager*innen einzustellen, die sich in den kommenden Jahren immer mehr als eigenständiges Berufsbild etablieren werden.
Über die Autor:innen
Prof. Dr. Martin Schmidt arbeitet als Data Science Manager bei der Deutsche Bahn AG. Er unterrichtet an der Digital Business University of Applied Science und ist ein assoziierter Forscher am Humboldt Institute for Internet and Society (HIIG). Martin hat Agrarwissenschaften studiert und im Bereich der Umweltmodellierung promoviert.
Prof. Dr. Marcel Hebing ist Professor für Data Science an der Digital Business University of Applied Science, Gründer der Impact Distillery und assoziierter Forscher am Humboldt Institute for Internet and Society (HIIG). Marcel hat in der Schnittmenge von Statistik, Informatik und Sozialwissenschaften promoviert.
Literatur
[1] H. Atwal, Practical DataOps (2020), Apress, DOI: 10.1007/978–1–4842–5104–1
[2] N. Eva, M. Robin, S Sendjaya, D. van Dierendonck and Robert C.Liden, Servant Leadership: A systematic review and call for future research (2019), The Leadership Quarterly, DOI: 10.1016/j.leaqua.2018.07.004
[3] R. Chang, So You Want to Become a Data Science Manager? (2019), Deliberate Data Science
[4] F. Iafrate, From Big Data to Smart Data (2015), John Wiley & Sons, Inc., DOI:10.1002/9781119116189
[5] B. Bhatti, What Are the Qualities of a Great Data Science Manager? (2017), Towards Data Science
[6] C. Shearer, The CRISP-DM Model: The New Blueprint for Data Mining (2000), Journal of Data Warehousing
[7] F. Provost and T. Fawcett, Data Science for Business (2013), O'Reilly Media, Inc., ISBN: 9781449361327
[8] B. Fournet, How to use the "Knowns" and "Unknows" Technique to Manage Assumptions (2019), The Persimmon Group
[9] D. Strom, For Technology Projects, Multiply by Pi (2008), Baseline
[10] G. M. Weinberg, An introduction to general systems thinking (1975), New York: Wiley
[11] M. Seiter, Business Analytics (2019), Vahlen, ISBN 978–3–8006–5871–8
[12] K. Jee, Why is it so Hard to Find Great Data Science Managers? (2019), Towards Data Science